
Python 3.14 - What didn't make the headlines
Yes, we know it's Pithon, the joke is 10 years old
Summary
PDB gets a lot of love, benefiting from the new shell features, a saner breakpoint strategy, and a nicer quitting experience.
Asyncio too, with loop policies and implicit loop creation going away, as well as a nice utility to see all running tasks live.
argparse now provides a much better
--helpand subcommand typo suggestions.Concurrency is not forgotten, with Linux getting a new default process creation strategy replacing “fork”, interpreters get their own pool executors,
ProcessPoolExecutorcan now terminate or kill all workers andSyncManageraccept sets.And loads of little things.
Xmas sockets
In October, I feel like a kid waiting for Xmas, except I already know what gifts I’m going to get. Free Threading, t-string, remote debugging, UUI7, and colors in the shell!
But what about the stuff I didn’t know about? The surprise visit of an uncle? My brother, who decided last minute to buy me stuff?
So uv self update && uv python upgrade 3.14, and let’s unwrap the goods!
PDB gets love
Despite how old school it is, I deeply like PDB, and if you really never got to use it, we have a little article for you.
In 3.14, the big bang is the fact you can now attach remotely to any running Python program. Yes, it is awesome and everyone is talking about it, but they really went the extra mile and polished many other details.
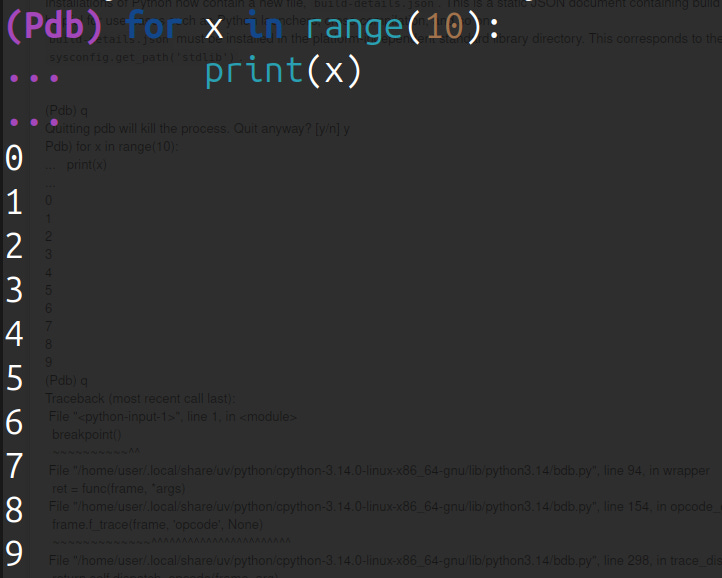
For example, one thing that has annoyed me for a long time when creating a breakpoint() is that it restarts a new PDB instance. If you are in a loop, it will create many of them, and of course, losing on the way the ability to type Enter and repeat the last command you used.
This is now fixed, and inline break points will reuse any previous debugger instance that existed.
This release also:
Removed the stack trace when you quit PDB. I always thought it was weird that quitting the debugger made you feel like crashing the program.
Adds a confirmation prompt to avoid exiting by mistake.
Inserts 4 spaces when using
<tab>. It used to insert a\t, meaning it would look like 2 spaces the first time and 8 the second. Since we now have multi-line in PDB (from 3.13), it was weird to have for-loop lines all over the place.And thanks to that, we also get auto-indent.
Adopts most of the goodies of the better Python shell, so the code you type in PDB will also be highlighted and have code-completion :)
Makes debugging
asynciobetter withpdb.set_trace_async()letting you callawaitinline in the REPL and a magic variable$_asynctaskcontains the current task.
Explicit is better even in asyncio
asyncio.get_event_loop used to be very surprising because it returned the current event loop if it existed, but if it didn’t... it created one.
This behavior has been deprecated since 3.10, and it will go away, along with the WHOLE policy system.
Ok, I didn’t see that one coming, as being able to use Policy objects to customize the loop creation process was there since the beginning of the lib, so it’s a big change, and I missed the deprecation warning.
To be clear, I hated the whole policy stuff. It is confusing, heavy, and a source of conflicts between 3rd parties. I’m really happy it’s going away.
So now people are expected to just always call asyncrio.run, optionally with loop_factory as a parameter, which is a much better, leaner, and simpler system. For edge cases when you want to really manage your loop manually (basically reimplement run()), you now have a Runner class and can communicate with the group of tasks using an Event object..
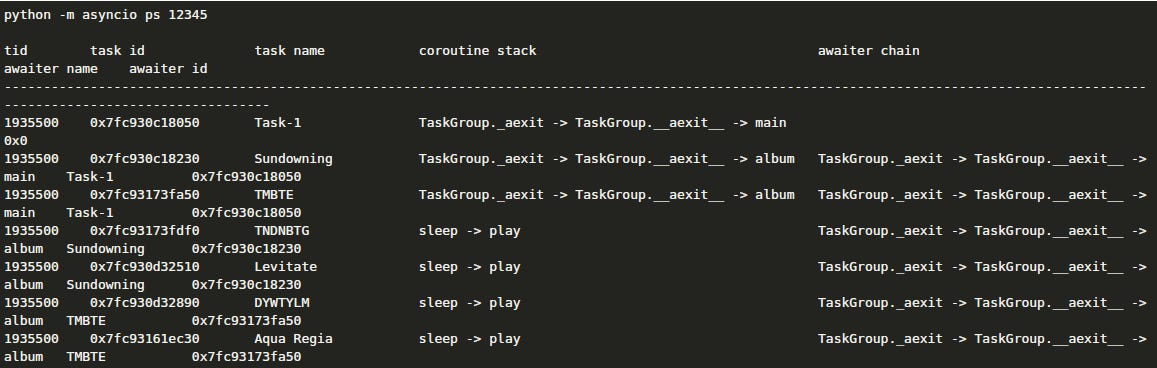
Introspection capabilities are also improving and exposed through two new commands:
python -m asyncio ps PIDattaches to a Python process from outside, and displays all asyncio tasks running in it in a table form, with their names, their coroutine stacks, and which tasks are awaiting them.python -m asyncio pstree PIDdoes the same but displays a visual async call tree:
argparse is now more user-friendly
Things take time, as the date of this request attests:
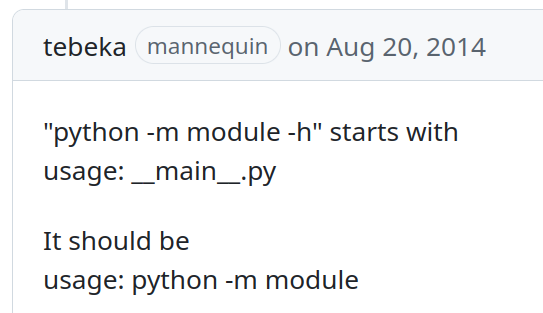
And today, argparse supports “python -m module” in help correctly. It’s the little things.
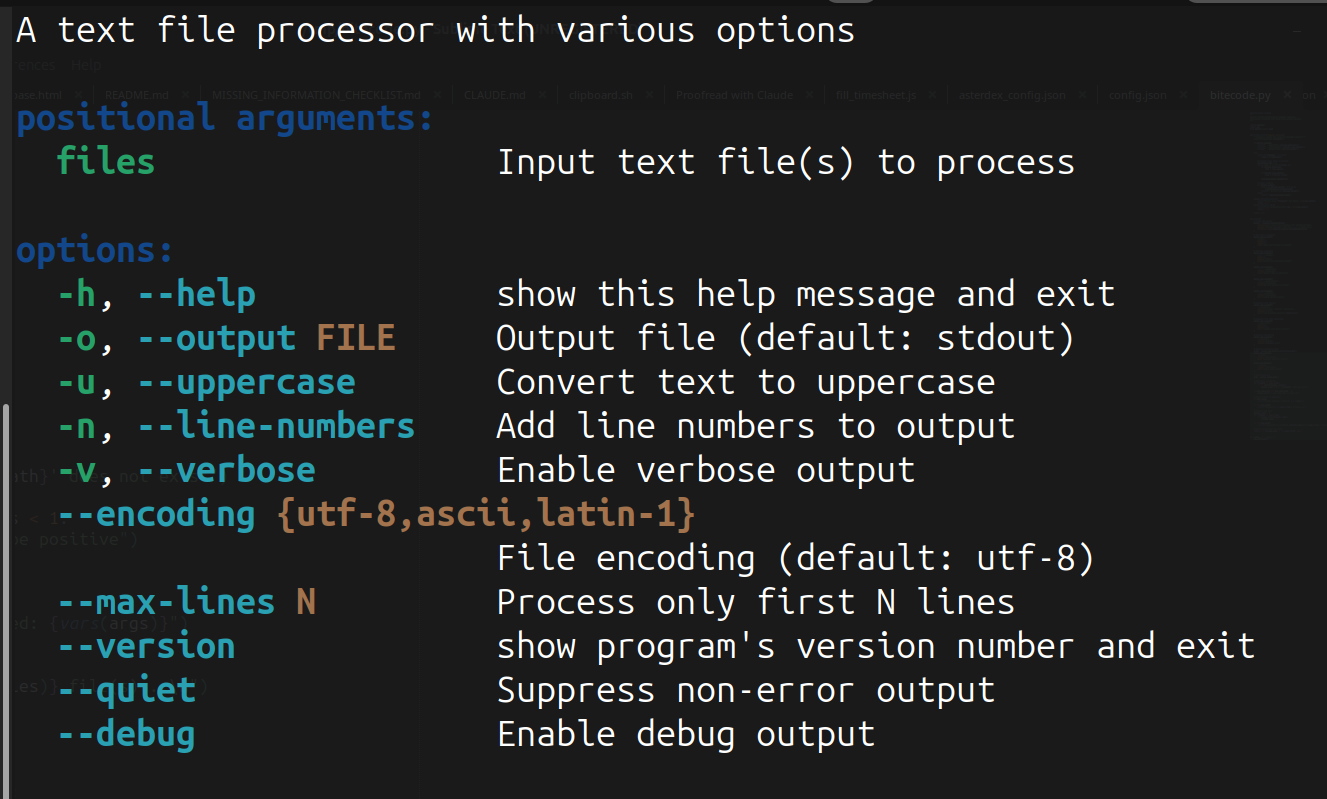
It also has a new ArgumentParser(suggest_on_error=True) parameter to let people know about typos on sub-commands, plus the help text is colorized:
I really like this trend of improving QoL for the unsexy tools we use every day. It all started with Pablo Galindo Salgado improving the stack trace and error messages (may he reach Valhalla for this), and now the REPL, PDB, argparse... This is great and has tremendous cumulative value.
A big thank you and much respect to all the people who do this work that doesn’t put you in the spotlight yet improves all our daily lives.
Concurrency options expand
Sure, free threading is the big thing in this release, and multi-interpreters, its direct competitor, is consolidating.
But there are other interesting developments in the concurrency area.
First, multiprocessing on Linux is changing too, adopting a different default strategy to create a new process. It used to be that “fork” was the default behavior when spawning a new process on that platform, but this could cause issues because forked processes inherit a lot from their parent process. This can conflict with shared resources, or if threads are used in the parent.
While regular forking is always available as an option (if you need perfs or compat), the new default strategy, “forkserver”, creates a brand new process using the “spawn” strategy. The said process is solely dedicated to forking. Then it forks this dedicated one instead of the parent for each new worker it needs, avoiding the sharing of unwanted things.
Setting the strategy can be global to the multiprocessing module, and in that case cannot be used more than once:
import multiprocessing as mp
def foo(q):
q.put(’hello’)
if __name__ == ‘__main__’:
mp.set_start_method(’fork’)
q = mp.Queue()
p = mp.Process(target=foo, args=(q,))
p.start()
print(q.get())
p.join()I would not recommend that. Instead, use a context and create a new process from it:
import multiprocessing as mp
def foo(q):
q.put(’hello’)
if __name__ == ‘__main__’:
ctx = mp.get_context(’fork’)
q = ctx.Queue()
p = ctx.Process(target=foo, args=(q,))
p.start()
print(q.get())
p.join()The first version is mostly useful with libraries that don’t let you pass a context.
Also note that stuff using PyInstaller and cx_Freeze (or any so-called frozen executable) will not work with “forkserver”, so you still need to use “fork” if you use those. Distributing Python programs to the end user is a gift that never stops giving.
Another change, one that is very welcome, is the ability to ensure all workers of a pool executor die. ProcessPoolExecutor is by far the simplest way to get basic multi-core concurrency in Python, but making sure all your workers are shut down is work you don’t want to do.
We now have a very heavy hammer for this and can call terminate_workers() (to politely send SIGTERM and the windows equivalent) to all of them. If it doesn’t work, you can escalate to the bazooka with kill_workers() which does what you think it does.
Still waiting for a good way to do the same with threads, since cancelling them is still a terrible experience in Python, and is one of the reasons there is so much talk about green threads right now, which would make that a much better experience.
On top of all this, we have a new pool, InterpreterPoolExecutor, which does the same of ThreadPoolExecutor and ProcessPoolExecutor, but for multiple interpreters. It looks and feels like ThreadPoolExecutor because that’s a subclass, but it has true parallelism since each thread runs with its own GIL. It also pays the same serialization price as ProcessPoolExecutor (using pickle), so I’m not sure I can find a use case for it. But I get why it’s there; you need to play with multi-interpreters if you want to find out if they are good at anything.
Oh, and I almost forgot: sets are now supported by SyncManager, joining lists and dicts into the exclusive club of data structures you can automatically synchronize between multiple processes (basically a poor man’s redis).
Do you have a moment to talk about our Lord and Savior strict?
zip(strict=True), the flag that forces all iterables to be of the same length, is a feature that, when it came out in 3.10, I didn’t think I would use nearly as much as I did. It saved my butt twice this month already, and I regularly activate the related B905 check on ruff.
>>> list(zip([1, 2, 3, 4], [1, 2, 3], strict=True))
Traceback (most recent call last):
File “<python-input-1>”, line 1, in <module>
list(zip([1, 2, 3, 4], [1, 2, 3], strict=True))
~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ValueError: zip() argument 2 is shorter than argument 1
>>> # or TypeError: list() takes no keyword arguments sometimes :DNow zip() having multiple iterables passed to it is a given; that’s its main job. But do you know which function can also do that, but that most people don’t use in that way?
map()
In Python, map() applies a function to each element of an iterable. Or does it? In fact, it can apply a function to elements of any number of iterables we want. You can do this with map():
>>> # always get the biggest element from those lists
>>> list(map(max, [8, 1, 7, 999], [-1, 82, 3, 4]))
[8, 82, 7, 999]Which is basically the equivalent of this comprehension list:
>>> [max(x, y) for x, y in zip([8, 1, 7, 999], [-1, 82, 3, 4])]
[8, 82, 7, 999]And you can spot the problem now, since this is the equivalent of a call to zip(). It has the same need for strict, and it therefore now has the parameter as well:
>>> list(map(max, [8, 1, 7, 999], [-1, 82, 3, ]))
[8, 82, 7]
>>> list(map(max, [8, 1, 7, 999], [-1, 82, 3], strict=True))
Traceback (most recent call last):
File “<python-input-0>”, line 1, in <module>
list(map(max, [8, 1, 7, 999], [-1, 82, 3], strict=True))
~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ValueError: map() argument 2 is shorter than argument 1And moar
We have new mime types. Lots of them! Woff fonts, mkv, jpeg2000, 7z, .deb, .ogg, .docx, .odg...
>>> mimetypes.types_map[’.deb’]
‘application/vnd.debian.binary-package’Plus a command line to get them:
❯ python -m mimetypes filename.7z
type: application/x-7z-compressed encoding: None
> python -m mimetypes --extension application/vnd.android.package-archive
.apkstrptimeadded todatetime.timeanddatetime.dateobjects. We don’t always need to get adatetime.datetimewhen we parse stuff \o/
>>> datetime.time.strptime(”12:45”, “%H:%M”)
datetime.time(12, 45)python -m http.server,which allows you to start a web server anywhere on your machine and serve the file in the current directory automatically, now supports SSL:
❯ python3.14 -m http.server -h | grep tls
[-p VERSION] [--tls-cert PATH]
[--tls-key PATH] [--tls-password-file PATH]
--tls-cert PATH path to the TLS certificate chain file
--tls-key PATH path to the TLS key file
--tls-password-file PATHpathlib.Pathnow has recursive directory copy/move and deletion, no more back and forth withshutil! The implementation is smart and provides two distinct methods to copy to and copy into, instead of making it dependent on the path passed, like bash does. Also, they cache stats information, and work across file systems. Got bitten by those before, so noice.
